

Data 2024, 9(6), 78; https://doi.org/10.3390/data9060078 - 6 Jun 2024
Abstract
►
Show Figures
Invasive intracranial electrodes are used in both clinical and research applications for recording and stimulation of brain tissue, providing essential data in acute and chronic contexts. The impedance characteristics of the electrode–tissue interface (ETI) evolve over time and can change dramatically relative to
[...] Read more.
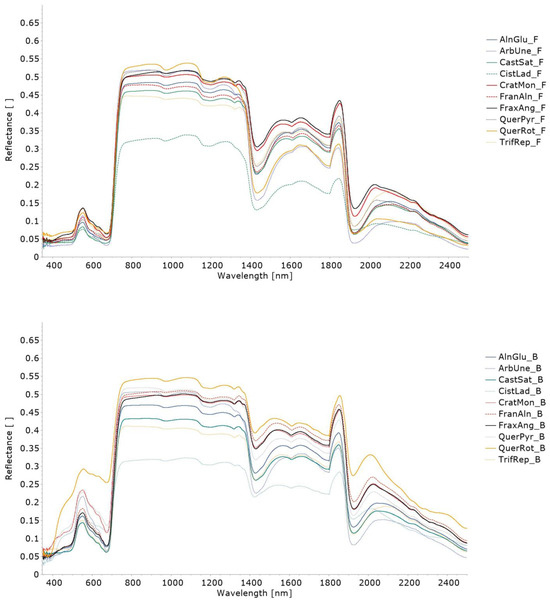
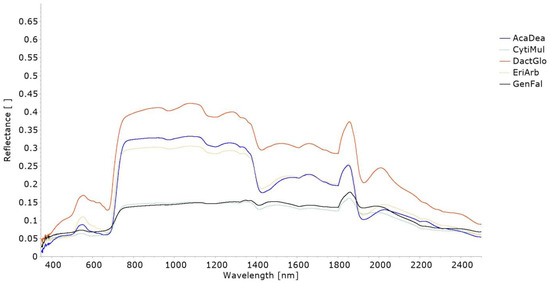
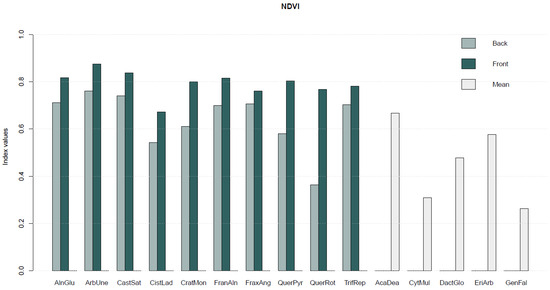
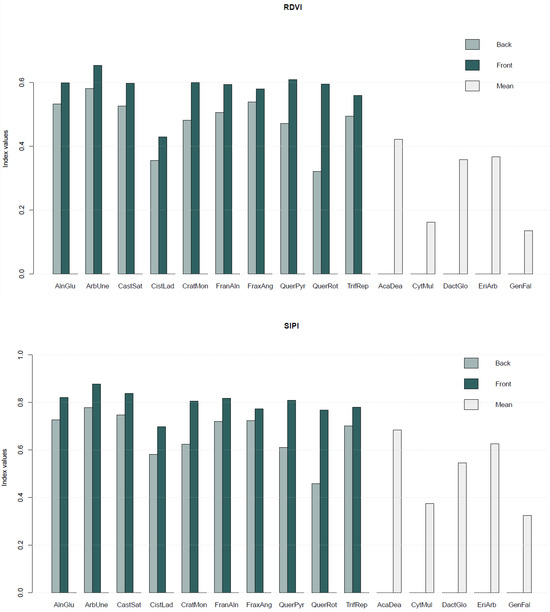
Invasive intracranial electrodes are used in both clinical and research applications for recording and stimulation of brain tissue, providing essential data in acute and chronic contexts. The impedance characteristics of the electrode–tissue interface (ETI) evolve over time and can change dramatically relative to pre-implantation baseline. Understanding how ETI properties contribute to the recording and stimulation characteristics of an electrode can provide valuable insights for users who often do not have access to complex impedance characterizations of their devices. In contrast to the typical method of characterizing electrical impedance at a single frequency, we demonstrate a method for using electrochemical impedance spectroscopy (EIS) to investigate complex characteristics of the ETI of several commonly used acute and chronic electrodes. We also describe precise modeling strategies for verifying the accuracy of our instrumentation and understanding device–solution interactions, both in vivo and in vitro. Included with this publication is a dataset containing both in vitro and in vivo device characterizations, as well as some examples of modeling and error structure analysis results. These data can be used for more detailed interpretation of neural recordings performed on common electrode types, providing a more complete picture of their properties than is often available to users.
Full article

Figure 1
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}